Segment Anything By Meta
Discover Meta AI's Segment Anything Model (SAM): a versatile tool for precise image segmentation with zero-shot generalization and extensive dataset training.
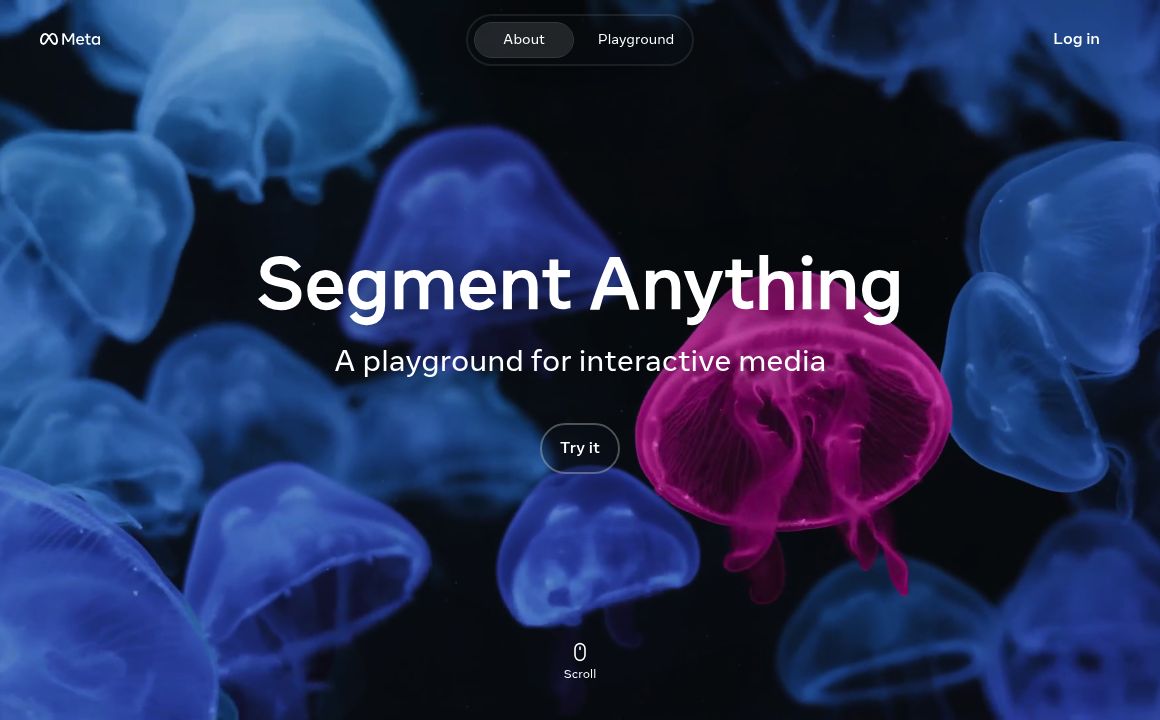
Segment Anything By Meta's Top Features
Frequently asked questions about Segment Anything By Meta
Top Segment Anything By Meta Alternatives
Trickle
0Transform your screenshots using GPT-4V with Trickle. Get insightful summaries and manage your digit...
/describe feature from Midjourney uses image-to-text technology to generate four descriptive prompts...
GeoSpy
0GeoSpy: AI-powered tool for precise image geolocation, perfect for OSINT, law enforcement, and journ...

Discover TextScan AI: the ultimate app for scanning, recognizing, and organizing text from various s...

Experience seamless photo organization with Picker AI's advanced AI technology. Enhance your photo m...
Use Vecteezy's AI Reverse Image Search to find conceptually related, fully licensable images efficie...